DB에 접속해서 작업을 할 때, DBeaver라는 무료 프로그램을 많이 사용하게 됩니다. 이 프로그램을 사용해서 Oracle, MSSQL, PPAS에 연결하여 사용하는 법을 알아볼게요!!
DBeaver 설치하는 방법
DB 관리 툴로 예전에는 Toad, Orange를 많이 사용했는데 라이선스가 필요하기 때문에 저처럼 프로젝트를 많이 옮겨 다니는 경우에는 바로 무료 툴을 받아 설치해서 사용하는 게 편하더라고요. 일단 설치부터 고고.
구글에 DBeaver를 검색하면 다운로드 페이지가 맨 위에 뜹니다.
Download 클릭해 들어가서 본인에게 필요한 OS 버전을 다운로드하여 설치하시면 끝입니다.

구글에서 DBeaver 검색하여 다운로드 받기
DBeaver로 DB 접속하기
예전에는 별도의 드라이버 설치 필요 없이, DB정보만 입력하고 방화벽만 뚫려 있으면 바로 접속이 되었던 것 같은데, 최근에 여러 프로젝트에서 새로 깔아 해보려니 드라이버를 따로 설정해줘야 하더라고요.
물론 드라이버 다운로드하겠느냐는 페이지가 뜨는데 접속이 되지 않거나 계속 오류가 표시되는 문제가 있었습니다.
결론은 디비의 종류마다 맞는 odbc 라이브러리를 구해줘서 라이브러리 패스에 추가해줘야 정상적으로 연결이 됩니다.
오라클 접속하기
처음에 커넥션을 만드는 템플릿에서 오라클을 선택합니다. IP, Port, DB SID, Username, Password 정보를 입력하고 왼쪽 하단의 Test Connection을 클릭했을 때 정상적으로 연결이 되면 성공인데요, 잘 되지 않으면 드라이버를 다시 세팅해줘야 합니다.
우측 하단의 Edit Driver Settings를 클릭하고 들어갑니다. Library탭으로 이동하여 기존에 있던 세팅 값을 다 지우고 "Add File"버튼을 눌러 odbc 라이브러리 파일을 추가합니다. 저의 경우 ojdbc8.jar를 넣으니 정상적으로 동작했습니다.

DBeaver 드라이버 세팅 변경하기
MSSQL 연결하기
이번 프로젝트에는 디비 종류도 참 다양합니다. 보통 오라클 MSSQL 정도인데, 이번엔 Postgre계열인 PAAS 디비까지 있습니다. 써본 적도 없는 디비인데, 여하튼 일단 MSSQL 먼저 도전합니다.
일단 연결 템플릿에서 SQLServer를 선택합니다. 연결 정보 세팅 후 Test Connection을 눌렀지만 역시나 바로 되지 않네요. Edit Driver Settings를 클릭하여 들어갑니다.
아까와 동일하게 라이브러리 탭으로 이동하여 기존 정보를 지우고 sql 라이브러리를 설정해줍니다. 저는 라이브러리가 없어서 구글에서 검색해서 다운로드하였습니다. 압축파일로 되어 있는데, 압축을 풀고 보시면 자바 버전별로 라이브러리가 제공되어 있습니다. 저는 8 버전의 라이브러리를 설정했더니 연결이 문제없이 되었습니다.
PPAS 연결하기
PostgreSQL과 PPA의 다른 점은?!
PostgreSQL은 EnterpriseDB 사에서 제공하는 무료 데이터베이스입니다. 오픈소스이며 확장성 및 표준 준수를 강조하는 객체-관계형 데이터베이스로 최근 많이 사용되는 추세이죠.
피파스라고 부르는 PPAS는 Postgres Plus Advanced Server의 약자로 PostgreSQL 기반이면서 오라클의 사용법을 그대로 사용할 수 있는 장점이 있는 디비입니다. 또한 오라클 기반으로 사용하는 애플리케이션을 실행할 수 있다는 것이 큰 강점이죠.
따라서 오라클이 비싸기 때문에 PPAS로 마이그레이션 하여 더 저렴하게 시스템을 연동할 수 있는 매우 큰 장점을 가지고 있어서 요즘 사용들을 많이 합니다.
그래서 그런지 지금 프로젝트에도 PPAS가 등장했네요. 처음 연결해봅니다. 두근두근..
DBeaver에서 PPAS 연결해보기
포스트그레 기반이니까, 템플릿을 포스트그레로 선택했습니다. 연결 정보 입력하고.. 연결 테스트. 역시 안됩니다. 얘는 PostgreSQL의 라이브러리를 넣어 놓아도 실행이 안됩니다. PPAS용 jdbc 라이브러리를 찾아야겠죠. 구글링을 해보니 라이브러리 파일 명이 edb-jdbc18.jar라고 합니다.
라이브러리를 못 찾아서 프로젝트 공유서버에 edb라고 쳐서 검색했더니 나왔습니다. PPAS를 깔고 나면 그 드라이브 뒤져보면 있다고 하니 그렇게 구하시면 될 듯합니다.
아까 했던 방법과 마찬가지로 Edit Driver Settings 버튼을 눌러 라이브러리를 기존에 있던 것 지우고 edb-jdbc18.jar를 넣었습니다. 그런데.. 연결이 안 됩니다!! 흙 ㅠㅠ 알고 보니 PostgreSQL의 템플릿을 사용했기 때문에 클래스 명과 URL이 다르게 되어 있기 때문이었네요.
PPAS 용 클래스 명은 com.edb.Driver이며 jdbc:edb://localhost:5444/edb 이런 식으로 jdbc url도 다릅니다. 다시 드라이버 세팅으로 들어가서 Setting 탭에 클래스 이름과 URL 템플릿을 변경해주었고 연결에 성공했습니다!!
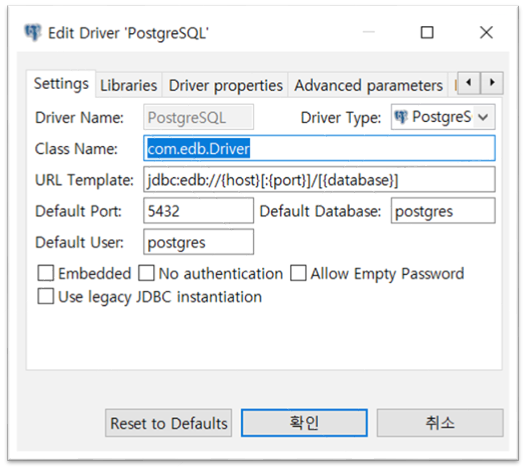
PPAS에 연결하기 위해 세팅 변경하기
여기까지 DBeaver를 사용해서 오라클, MSSQL, PPAS에 연결하는 방법을 알아보았습니다.
'프로그래밍 > DB' 카테고리의 다른 글
| DBeaver 설정 백업 (작업 환경 백업) (1) | 2023.11.27 |
|---|---|
| Maria DB substring, substring_index (0) | 2023.06.27 |
| MSSQL MDF, LDF SHRINK 파일 용량 줄이기 (0) | 2021.03.04 |
| MSSQL 프로시져 관련 내용 (0) | 2020.10.22 |
| ORACLE / MSSQL 같은 내용 비교 (0) | 2020.10.22 |













